Algorithm
Videos
Photos
In mathematics and computer science, an algorithm is a finite sequence of mathematically rigorous instructions, typically used to solve a class of specific problems or to perform a computation. Algorithms are used as specifications for performing calculations and data processing. More advanced algorithms can use conditionals to divert the code execution through various routes and deduce valid inferences, achieving automation eventually. Using human characteristics as descriptors of machines in metaphorical ways was already practiced by Alan Turing with terms such as "memory", "search" and "stimulus".

Ada Lovelace's diagram from "Note G", the first published computer algorithm
Mathematics
Videos
Photos
Mathematics is an area of knowledge that includes the topics of numbers, formulas and related structures, shapes and the spaces in which they are contained, and quantities and their changes. These topics are represented in modern mathematics with the major subdisciplines of number theory, algebra, geometry, and analysis, respectively. There is no general consensus among mathematicians about a common definition for their academic discipline.
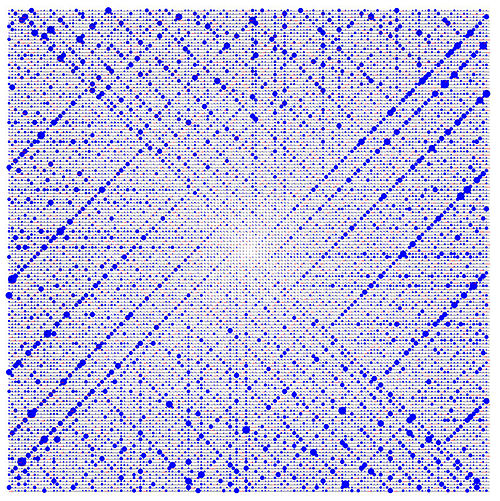
This is the Ulam spiral, which illustrates the distribution of prime numbers. The dark diagonal lines in the spiral hint at the hypothesized approximate independence between being prime and being a value of a quadratic polynomial, a conjecture now known as Hardy and Littlewood's Conjecture F.

On the surface of a sphere, Euclidean geometry only applies as a local approximation. For larger scales the sum of the angles of a triangle is not equal to 180°.

The Babylonian mathematical tablet Plimpton 322, dated to 1800 BC

A page from al-Khwārizmī's Algebra