Meta-analysis is the statistical combination of the results of multiple studies addressing a similar research question. An important part of this method involves computing an effect size across all of the studies; this involves extracting effect sizes and variance measures from various studies. Meta-analyses are integral in supporting research grant proposals, shaping treatment guidelines, and influencing health policies. They are also pivotal in summarizing existing research to guide future studies, thereby cementing their role as a fundamental methodology in metascience. Meta-analyses are often, but not always, important components of a systematic review procedure. For instance, a meta-analysis may be conducted on several clinical trials of a medical treatment, in an effort to obtain a better understanding of how well the treatment works.

Graphical summary of a meta-analysis of over 1,000 cases of diffuse intrinsic pontine glioma and other pediatric gliomas, in which information about the mutations involved as well as generic outcomes were distilled from the underlying primary literature.
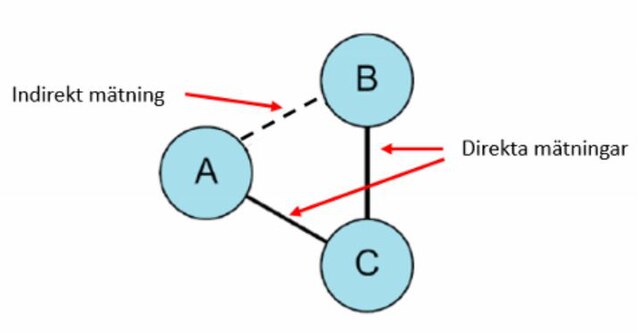
A network meta-analysis looks at indirect comparisons. In the image, A has been analyzed in relation to C and C has been analyzed in relation to B. However the relation between A and B is only known indirectly, and a network meta-analysis looks at such indirect evidence of differences between methods and interventions using statistical method.
A funnel plot expected without the file drawer problem. The largest studies converge at the tip while smaller studies show more or less symmetrical scatter at the base
A funnel plot expected with the file drawer problem. The largest studies still cluster around the tip, but the bias against publishing negative studies has caused the smaller studies as a whole to have an unjustifiably favorable result to the hypothesis
Metascience is the use of scientific methodology to study science itself. Metascience seeks to increase the quality of scientific research while reducing inefficiency. It is also known as "research on research" and "the science of science", as it uses research methods to study how research is done and find where improvements can be made. Metascience concerns itself with all fields of research and has been described as "a bird's eye view of science". In the words of John Ioannidis, "Science is the best thing that has happened to human beings ... but we can do it better."
An exemplary visualization of a conception of scientific knowledge generation structured by layers, with the "Institution of Science" being the subject of metascience
Funding for climate research in the natural and technical sciences versus the social sciences and humanities
Number of authors of research articles in six journals through time
ArXiv's yearly submission rate growth over 30 years