DNA
Videos
Deoxyribonucleic acid is a polymer composed of two polynucleotide chains that coil around each other to form a double helix. The polymer carries genetic instructions for the development, functioning, growth and reproduction of all known organisms and many viruses. DNA and ribonucleic acid (RNA) are nucleic acids. Alongside proteins, lipids and complex carbohydrates (polysaccharides), nucleic acids are one of the four major types of macromolecules that are essential for all known forms of life.

Impure DNA extracted from an orange

T7 RNA polymerase (blue) producing an mRNA (green) from a DNA template (orange)

A current model of meiotic recombination, initiated by a double-strand break or gap, followed by pairing with an homologous chromosome and strand invasion to initiate the recombinational repair process. Repair of the gap can lead to crossover (CO) or non-crossover (NCO) of the flanking regions. CO recombination is thought to occur by the Double Holliday Junction (DHJ) model, illustrated on the right, above. NCO recombinants are thought to occur primarily by the Synthesis Dependent Strand Annealing (SDSA) model, illustrated on the left, above. Most recombination events appear to be the SDSA type.
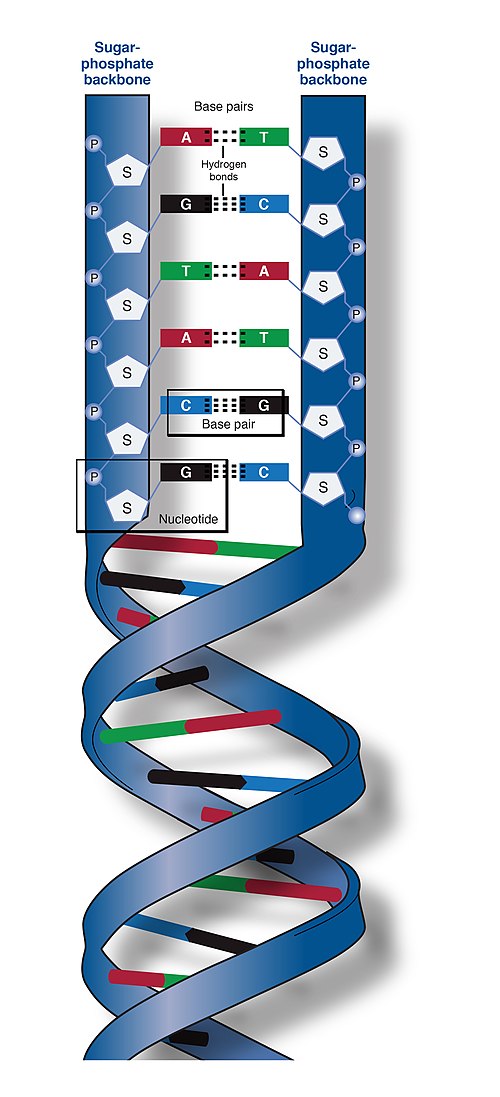
Nucleic acid double helix
Videos
In molecular biology, the term double helix refers to the structure formed by double-stranded molecules of nucleic acids such as DNA. The double helical structure of a nucleic acid complex arises as a consequence of its secondary structure, and is a fundamental component in determining its tertiary structure. The structure was discovered by Rosalind Franklin and her student Raymond Gosling, but the term "double helix" entered popular culture with the publication in 1968 of The Double Helix: A Personal Account of the Discovery of the Structure of DNA by James Watson.

Base pair geometries